Pretrained vision-language-action (VLA) policies show promising zero-shot generalization,
but often fail under deployment-time distribution shift, leading to decreased robustness
and inconsistent instruction following. While prior work commonly tackles this by
finetuning on in-distribution data, it assumes demonstrations collected on tasks in the
target environment. In this work, we propose DreamSteer, a
deployment-time steering framework for pretrained VLAs without any finetuning or
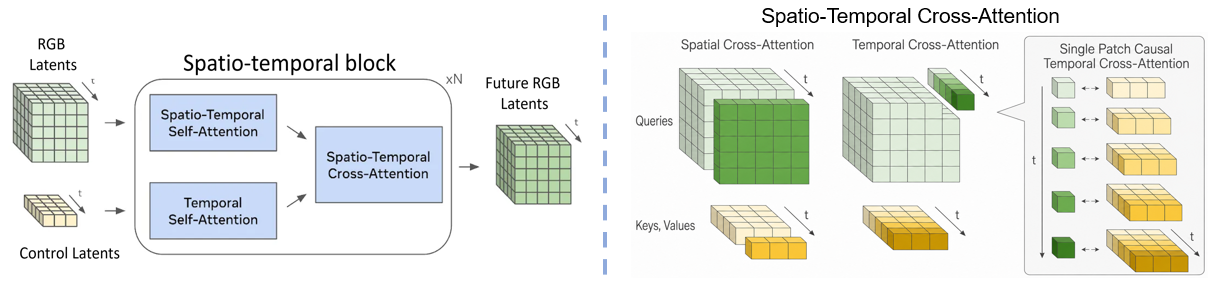
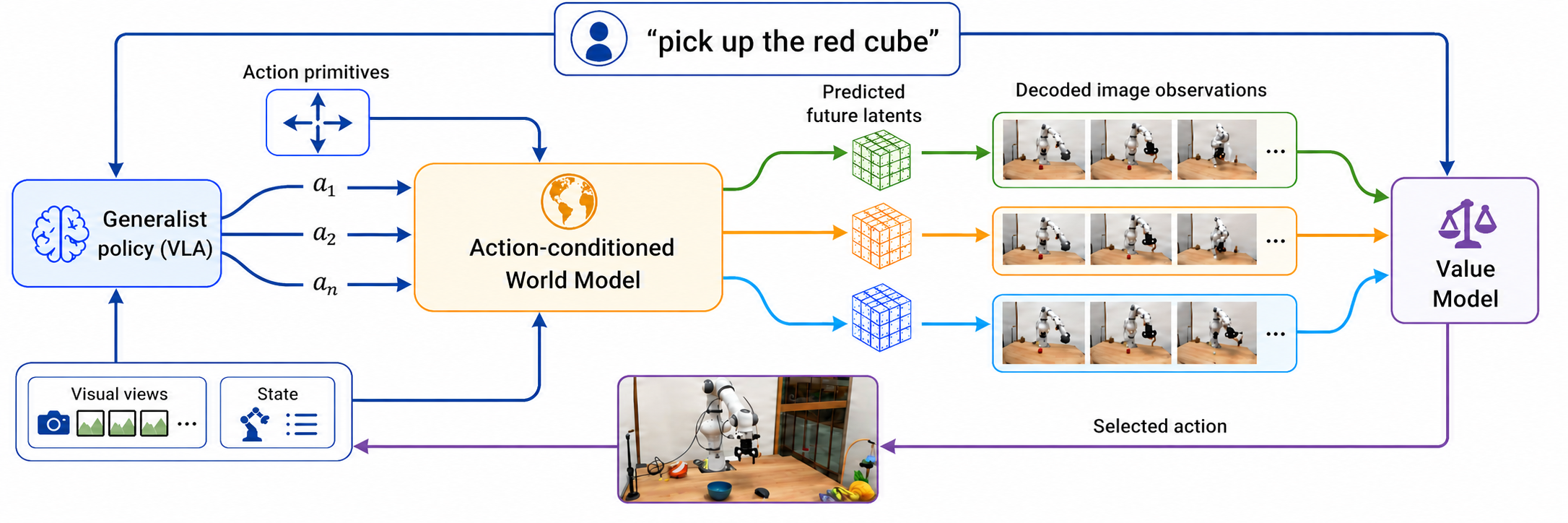
parameter modifications. The key insight in DreamSteer is to leverage a
latent world model and a value model to steer pretrained VLA
policies. During deployment, DreamSteer samples candidate action chunks from a VLA
policy and predefined motion primitives, imagines their outcomes using an
action-conditioned latent world model, and ranks the imagined trajectories with a
language-conditioned value model. Across four real-world manipulation benchmarks with
unseen objects, DreamSteer improves task success rate from 23.75% to
66.25% and instruction-following accuracy from
38.75% to 56.25% over the base VLA policy.